‘eating doughnut’
![]() Video passed through an object-recognition-algorithm (YOLOv6). Source—66 Scenes from America, Jørgen Leth (1982). ︎︎︎︎︎︎
Video passed through an object-recognition-algorithm (YOLOv6). Source—66 Scenes from America, Jørgen Leth (1982). ︎︎︎︎︎︎
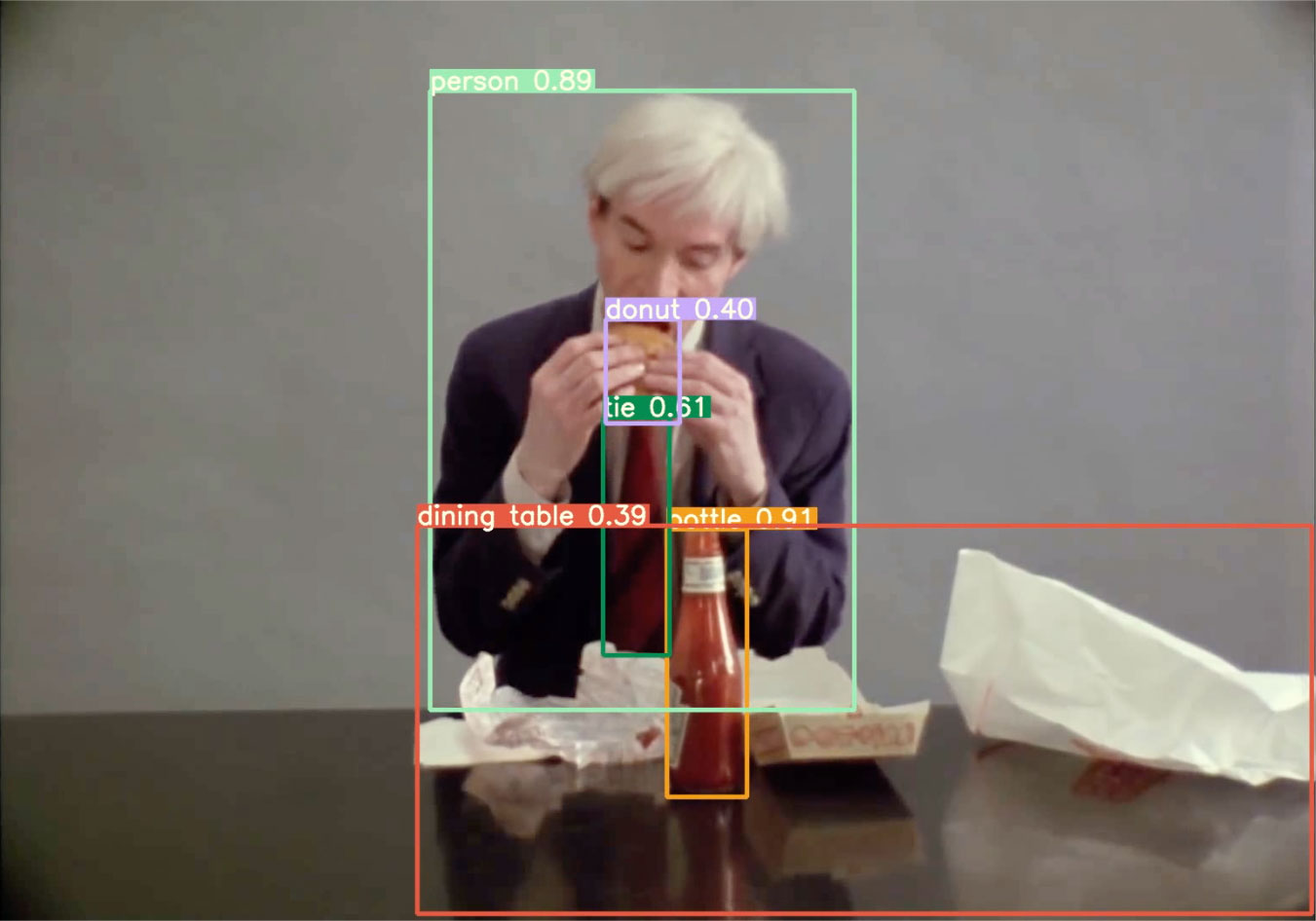

The reality of so-called artificial intelligence (AI) is that many algorithms labelled as such are, in fact, imperfect models at risk of making erroneous inferences. Object recognition and human-action-recognition (HAR) algorithms are particularly at risk as they can have difficulty ‘recognising’ the nuances of human movement and gesture in relation to other things. Eating actions are among the most difficult to classify as the algorithm needs to distinguish between different types of food.

The food may appear small, obscured behind a hand or already partially eaten. The act of ‘eating burger’1 is often confused with ‘eating doughnut’. Dancing actions are also difficult (is it ‘swing dancing’ or ‘salsa dancing’?), as well as classes centred on a specific body part, such as ‘massaging feet’ and ‘shaking head’. A HAR model also has difficulty distinguishing between drowning and ‘swimming backstroke’.

A HAR algorithm may not reflect the reality you think you know. Images discomposed in a search for meaning are contingent on the flimsy ‘worldview’ of a dataset, a rarefaction of ‘all the things in the world’. The image is ‘refracted’ through a medium to emerge on the other side with its elements parsed and reassembled into weird new relationships. Through analogical reasoning and adherence to the nearest-neighbour principle, ‘playing didgeridoo’, among other instruments, is remapped onto the triangulation between mouth and hands in a seemingly effortless superimposition.

Video passed through a human-action-recognition algorithm ︎︎︎
Source—66 Scenes from America, Jørgen Leth (1982).
Source—66 Scenes from America, Jørgen Leth (1982).
(1) ‘eating burger’, ‘eating doughnut’, ‘swing dancing’, ‘salsa dancing’, ‘massaging feet’, ‘shaking head’, and ‘swimming backstroke’ are labels that have been assigned to classes of human actions in the Kinetics 400 dataset. Kay, W. et al. (2017) The Kinetics Human Action Video Dataset. Available at: arXiv:1705.06950v1 [cs.CV].